Chapter 3 Linear Outlier Detection
Regression starts with a linear model – many nonlinear methods are essentially extensions of linear methods. It is therefore sensible to begin this exposition with the linear methods, as well. We will first discuss linear models and then go on to discuss principal component analysis.
3.1 Linear Models
Linear Models are the most common regression technique and therefore a fitting start for a discussion of outlier detection algorithms using regression.
3.1.1 Motivation
Consider a few examples: suppose we compare the performance of students a lecture with their grades after the exam. Alternatively, we compare the level of education with the pay grade or the forecast with the actual weather. In all these cases, our intuition for outliers is rather clear: how strongly does the latter dimension deviate from the prediction of the former? These are instances of a directed model which may be implemented by a linear model. We therefore extract a certain feature which should conform to the prediction by the other feature. A larger deviation would imply a stronger possibility that a certain data point is an outlier.
3.1.2 Definition and implementation in R
The implementation is simple:
Fit a linear model with the function
lm.Predict the data points and determine the residuals with
predict.
3.1.3 Example application
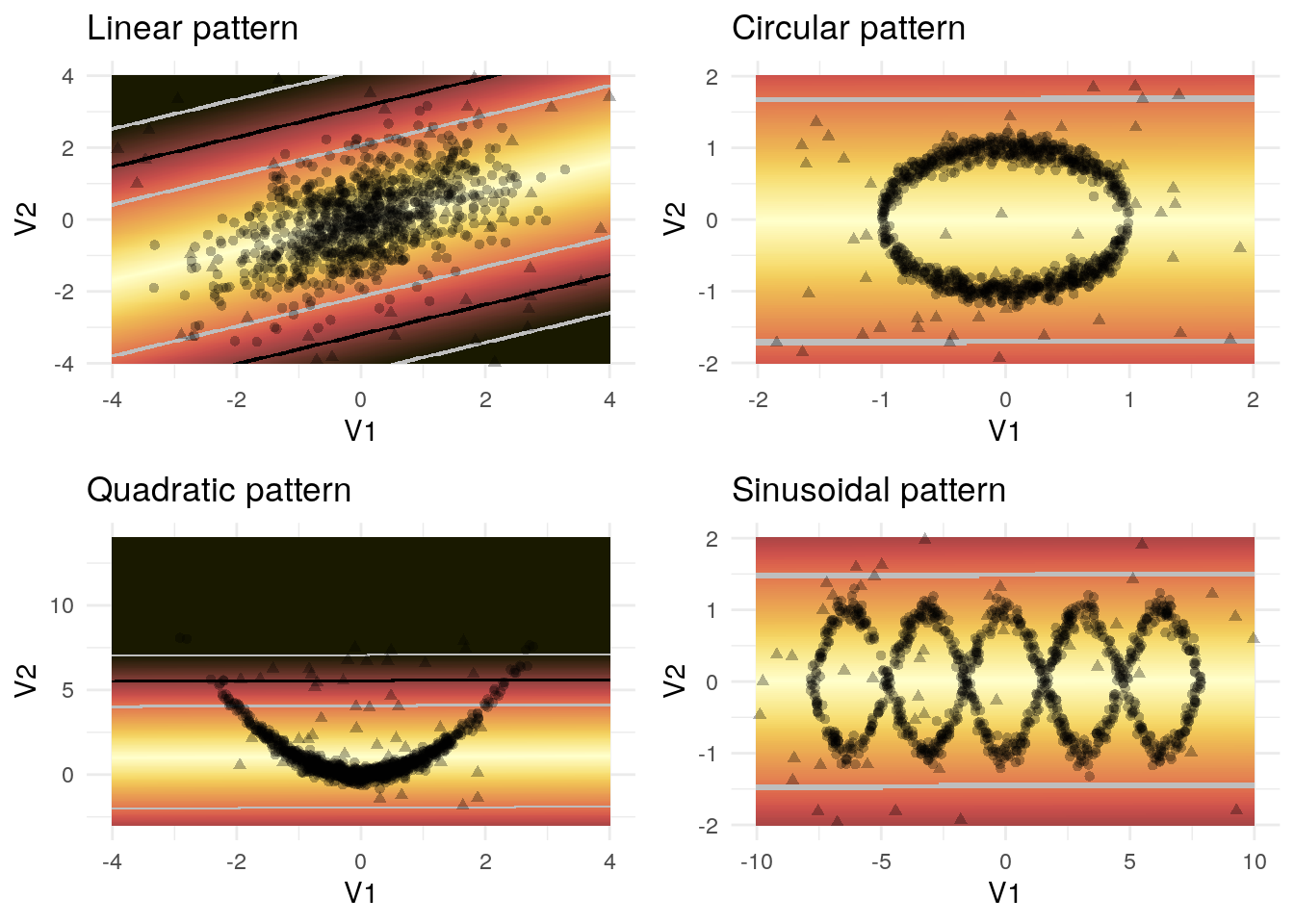
Figure 3.1: Outlier detection using linear models
The application of this method to the example data can be found in figure 3.1. The linear pattern is recognized rather well which is partly due to the evenly distributed outliers. The algorithm fails to recognize the correct patterns in the nonlinear cases for obvious reasons.
3.1.4 Data compression and correction
Data compression would be achieved by leaving out the predicted variable and decoding the compressed pattern by predicting it according to the fitted linear model. Data correction would correspond to replacing the true value of the predicted variable by its prediction from the other variables.
3.1.5 Discussion
It is important to emphasize at this point that such a simple model will scarcely be useful for many different reasons. From a practical point of view, the dynamics in most real-world datasets cannot be captured by a linear assumption. This restriction applies to all methods in this chapter. However, this method can easily be extended to arbitrary regressions which are able to capture more complex relationships. This enables us to extract features, prevent overfitting and adress other issues with the help of regression methods. On the other hand, special knowledge is necessary to apply a directed model – after all, we need to know which variable to predict. In the aforementioned examples, this has worked – in particular, these methods may often be applied in a spatiotemporal context (Aggarwal 2017, ch. 9 and 11) in which we predict data at time point \(t\) with the data at time point \(t-1\), for instance. In many cases, however, there is no obvious special variable to predict. Paulheim and Meusel (2015) presented the ALSO approach which essentially fits a regression for every variable. This approach has the advantage that it requires no special knowledge while retaining the adaptability of these regression methods.
It is also important that many regression methods are susceptible to the very problem they must adress in this context, namely outliers. Fahrmeir et al. (2013) point out that even a single outlier may affect the fitted hyperplane to an arbitrarily large degree. In order to solve this issue, it is possible to use an iterated approach where in the first step, we attempt to characterize the outliers and then fit another regression after removing the obvious outliers. Several iterations would possibly adress this issue. This approach may be discussed within the more general context of ensemble methods which Aggarwal (2017) adresses in chapter 6. This is, however beyond the scope of this report.
3.2 Principal Component Analysis
3.2.1 Motivation
Another possibility to remove the directedness of the approach in the last section is by considering the orthogonal prediction error. Consider figure 3.2.
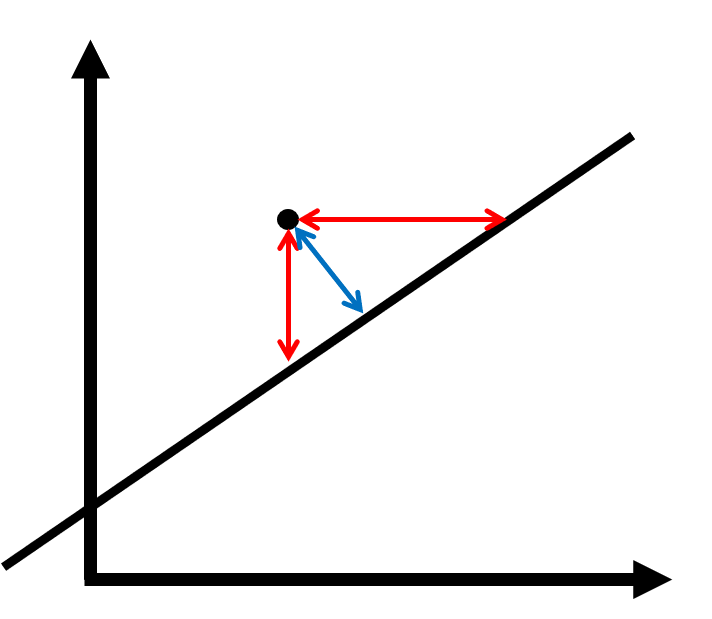
Figure 3.2: Orthogonal error (blue) and directed error (red)
A directed regression would attempt to minimize the length of one of the red arrows. In contrast, orthogonal regression attempts to minimize the orthogonal error, which corresponds to the blue arrow. This regression method is symmetrical which removes the choice of the predicted variable. It can be shown that this task is equivalent to the following two tasks:
- Solving a regression problem where all variables are used as covariates, the predicted variable \(Y\) is constantly zero and the regression coefficients as a vector have unit norm,
- Determining the linear combination with the least variance, i. e. the last principal component.
Principal component analysis (PCA) is therefore a natural extension of orthogonal regression which we will explore in this section.
3.2.2 Definition
As PCA is covered in most undergraduate degrees in statistics, I will leave out the mathematical definition and refer the interested reader to chapter 11 of Härdle and Simar (2015). Intuitively, a PCA attempts to capture as much information within the first linear combinations of the variables as possible. The different principal components are therefore uncorrelated. This approach is especially sensible in cases where high dimensionality poses a problem, in particular if humans need to deal with the data. Usually, a cutoff point \(k\) is chosen and only the first \(k\) prinicipal components are retained. In order to chose this cutoff point, different techniques are possible.
In the case of outlier analysis, the cutoff point is often assumed to be zero, i. e. we computed the weighted average squares of all principal components. This is because the cutoff point introduces a new parameter and these parameters are especially difficult to fit in the context of outlier analysis. On the other hand, we can scarcely make an informed choice regarding the cutoff point as principal components almost never have an intuitive interpretation. In particular, discarding the need for an informed choice was our initial motivation for principal components analysis. Furthermore, the standard deviation of the first principal components is usually large and their variation does not have a huge influence on the outlier score, anyway.
In R, this method may be implemented by the following steps:
- Fit the principal components analysis using
prcomp, e. g.:model <- prcomp(x). - Predict the principal components using
predict, e. g.:pcs <- predict(model). - Compute the score. You can access the standard deviations of the different principal components via the
sdevelement of the list whichprcompreturns, e. g.:score <- pcs ^ 2 %*% model$sdev.
3.2.3 Example application
Figure 3.3 shows the result of the PCA outlier detection.
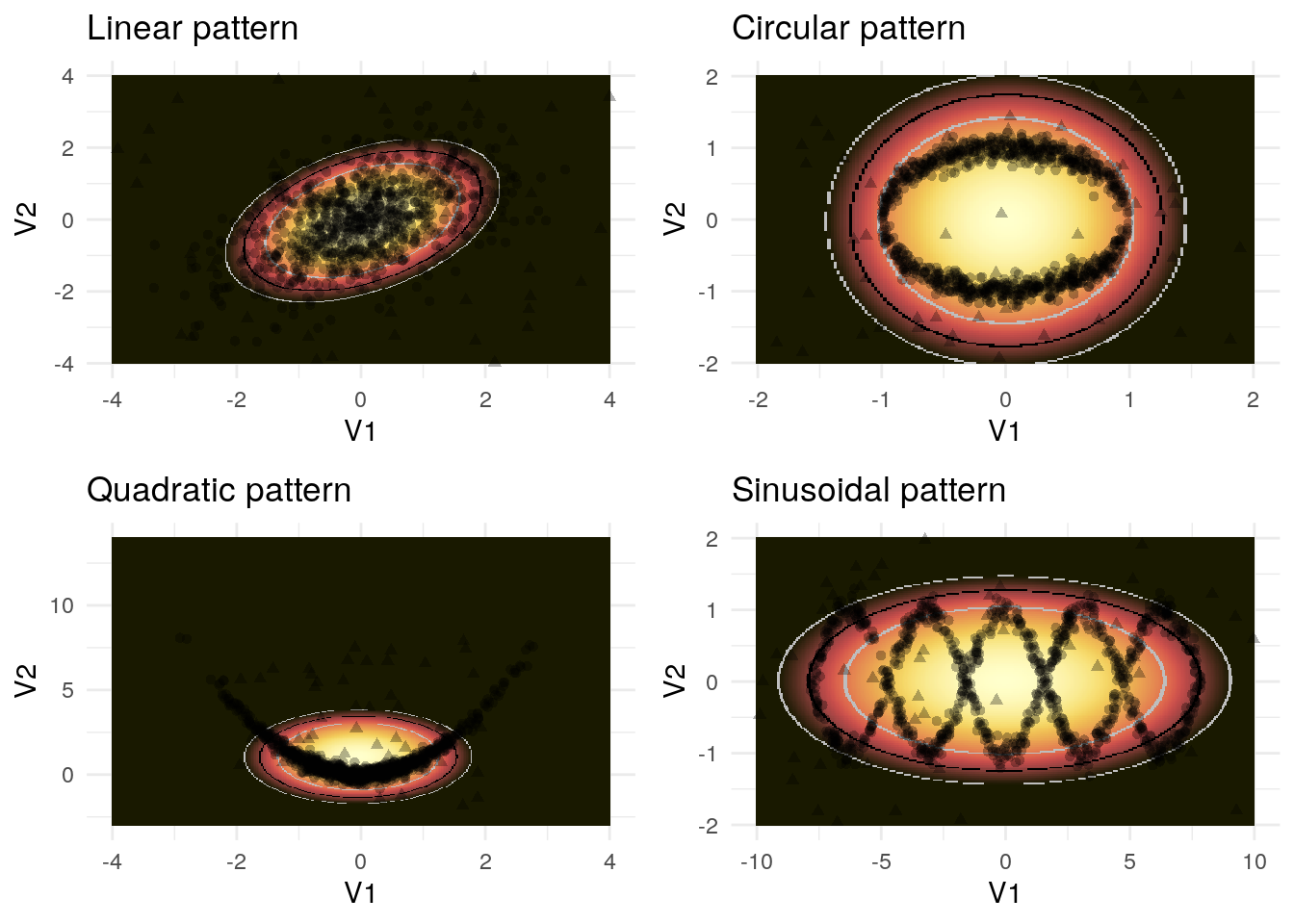
Figure 3.3: Outlier detection using principal components analysis
Notably, the outlier score now has elliptic levels (in contrast, the linear model yielded straight levels). This demonstrates that both principal components are part of our outlier score. In the case of the linear pattern, the assumption that both dimensions are relevant to the outliers is simply wrong which is why the pattern recognition is not accurate. In the circular case, the method actually recognizes that the points outside the circle are outliers. Due to the method’s linear assumption, it is not able to recognize that there are outliers within the circle as well. The method is not adept at recognizing the quadratic and sinusoidal pattern either.
3.2.4 Data compression and correction
With principal component analysis, data may be compressed arbitrarily strongly, as we may discard as many principal components as we would like. Encoding would therefore happen by computing \(T=XP\) and discarding the last principal components. \(\tilde{X}=TP^T\) would decode \(T\). The data may also be corrected in this way. The underlying assumption is that the last components are driven by noise and the correct value is therefore likely to be constant, i. e. zero.
Both compression and correction require a hard PCA, i. e. one with non-trivial cutoff points. This comes with its advantages and disadvantages.
3.2.5 Discussion
In the context of outlier analysis, a soft PCA is mostly a better choice than a hard PCA for the aforementioned reasons and we have solved the problem of assymmetry which we had with the linear model. On the other hand, the PCA is still restricted by linear assumptions. In particular, the soft PCA is equivalent to the Mahalanobis score, a simple probabilistic outlier score. The point of using principal components analysis, however, is that we can find a non-linear extension and the so called kernel trick which enables us to do that will be the subject of the first section in the next chapter. This computational technique was developed for Support Vector Machines (SVMs), a popular Machine Learning Algorithm (Aggarwal 2015, sec. 10.6). Indeed, SVMs have found their way into outlier analysis, as well. However, their performance depends on the choice of certain hyperparameters in an intransparent manner and this method is therefore less reliable. (Manevitz and Yousef 2001) As introducing SVMs would require introducing Lagrange optimizers, I have decided to discard this technique for the present report.
Finally, I will point out that besides the non-linear extensions which we will discuss, techniques have been developed to fit PCA to noisy or missing data (Bailey 2012) which can be of use in the context of outlier detection, as well.
References
Aggarwal, Charu C. 2015. Data Mining. 1st ed. Springer International Publishing.
Aggarwal, Charu C. 2017. Outlier Analysis. Springer Publishing Company, Incorporated.
Bailey, Stephen. 2012. “Principal Component Analysis with Noisy and/or Missing Data.” Publications of the Astronomical Society of the Pacific 124 (September): 1015–23.
Fahrmeir, Ludwig, Thomas Kneib, Stefan Lang, and Brian Marx. 2013. Regression - Models, Methods and Applications.
Härdle, Wolfgang Karl, and Léopold Simar. 2015. Applied Multivariate Statistical Analysis. 4th ed. Berlin, Heidelberg: Springer.
Manevitz, L. M., and M. Yousef. 2001. “One-class SVMs for Document Classification.” Journal of Machine Learning Research 2: 139–54.
Paulheim, Heiko, and Robert Meusel. 2015. “A decomposition of the outlier detection problem into a set of supervised learning problems.” Machine Learning 100 (2): 509–31. https://doi.org/10.1007/s10994-015-5507-y.